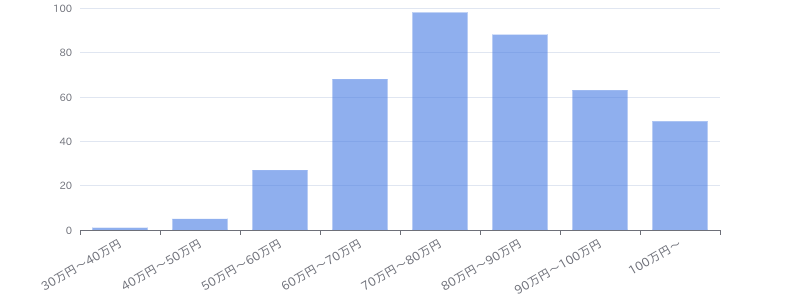
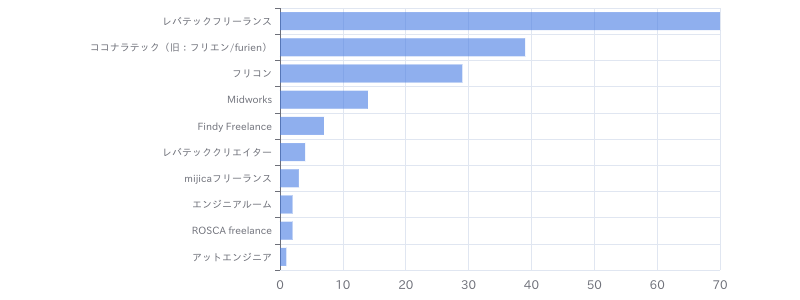
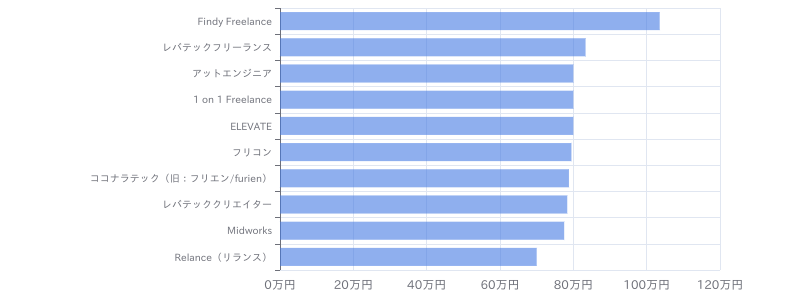
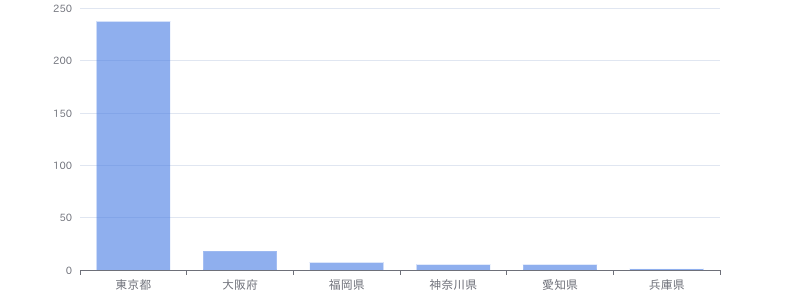
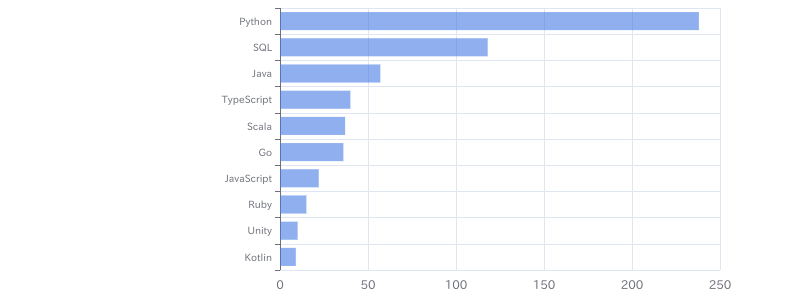
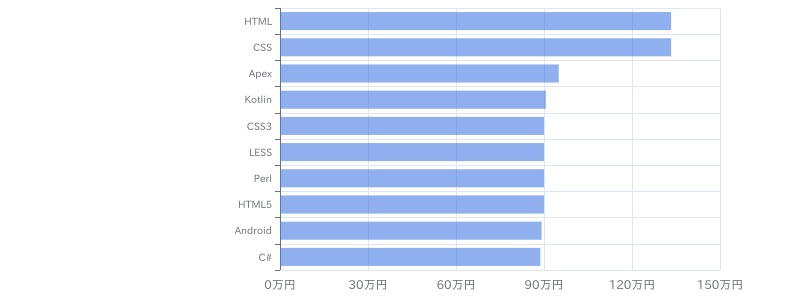
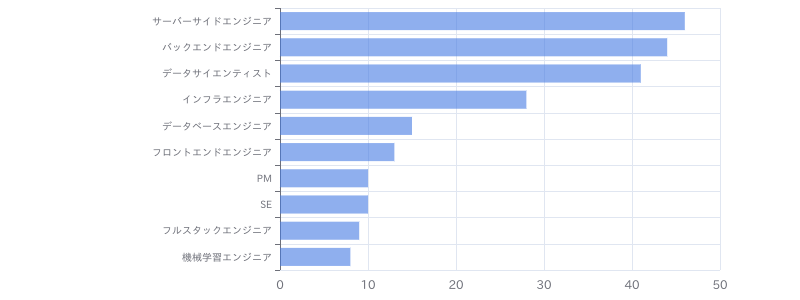
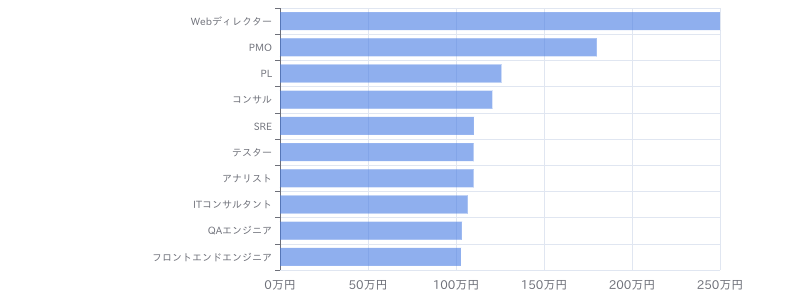
(リモート)【Python、SQL】メーカー向けデータ利活用支援
業務委託(フリーランス)
PythonSQLAWSRedshiftGlue
バックエンドエンジニア
作業内容 ・python(実行はRedshift)からSparkSQLへの移行案件
・SparkSQLの移行実装は終えているが、不具合が発生しているためその修正及び試験を実施
・環 境:AWSGlue/Redshift/SparkSQL/python
-SQL実装経験(サブクエリ・外部結合を構築可能)
SE/PG募集(Java/TypeScript/Python/Azure)
業務委託(フリーランス)
JavaPythonSparkAzureDockerTypeScript
PGSE
作業内容 フルリモート環境にて、仕様書を基に主体的に開発(コーディング)を行っていただきます。
仕様が不明瞭な箇所については、課題管理表・チャット等でクライアントへの確認が発生します。
(リモート)【Python、Shell】某製造小売業におけるデータ設計開発業務
業務委託(フリーランス)
PythonShellSparkAWS
バックエンドエンジニア
作業内容 AWS を活用したデータ基盤(DWH/データレイク)の設計・構築・運用およびデータパイプライン/モデル開発・運用業務をお願いします。
(リモート)データ分析ツールの導入・開発保守【Python】
業務委託(フリーランス)
Python
バックエンドエンジニア
作業内容 ・データ分析、利活用ツールの導入、保守開発等(開発より調査やドキュメント作成の方が多い想定)
・Azureへの移行
【データエンジニア】大規模データ基盤構築(Databricks、Tableau)(フルリモート)
業務委託(フリーランス)
PythonTableau
作業内容 既存のTableau環境にDatabricksを追加採用し、社内外データを一元的・効率的に管理できる統合データ基盤を構築するプロジェクトです。
データパイプラインの設計・構築を主要業務としてご担当いただきます。
(リモート)エンタメSaaSサービスにおけるデータエンジニア
業務委託(フリーランス)
JavaPythonSQLAWSGoogle Cloud PlatformBigQueryGlueTerraform
作業内容 現在、AWS(データレイク)とGCP(DWH)を組み合わせたハイブリッドクラウド基盤を構築中です。
この基盤をスケールさせ、俊敏なデータ活用を全社に浸透させるために、AWSGlue や BigQueryを活用したデータパイプライン開発を担当いただくデータエンジニアを募集します。
サービス運営・ビジネス分析・出版社支援など多様な活用ニーズに応えるためのデータ基盤構築をお任せします。
▪️データレイク/ETL 基盤の構築
・AWS Glue(Apache Spark)による分散処理・ETL 開発
・S3/Lake Formation を用いたデータ管理・セキュリティ設計
▪️BigQuery ベースの DWH 環境整備
・AWS → GCP 間データ連携パイプラインの最適化
・BigQuery によるデータモデリング・クエリ最適化
▪️IaC を軸としたマルチクラウド管理
・Terraform による環境差分管理・自動化
▪️品質管理・運用効率化
・Airflow などのワークフロー管理と CI/CD 整備
・データ品質テストの自動化
【Databricks/PySpark/Azure】商用車ロジスティクス可視化基盤のデータ処理最適化
業務委託(フリーランス)
ScalaSparkAzure
サーバーエンジニア
作業内容 【作業内容】
・Databricks(PySpark, Scala)環境のパフォーマンス最適化を行います。
・大規模データ処理の実装・改修を担当します。
・Azureデータ基盤のパフォーマンス改善を行います。
・保守・構成管理およびリファクタリングを担当します。
【Databricks/SQL/Python/フルリモート】データ解析システム構築支援案件
業務委託(フリーランス)
PythonSQLHadoopSparkApacheGitKafka
サーバーサイドエンジニア
作業内容 【募集背景】
【作業内容】
Databricksによるデータ解析システムの構築支援(設計/実装/テスト)を行います。
【求める人物像】
受け身や指示待ちでなく、主体的に業務に取り組み積極的に行動できる方。
チームメンバーとも積極的にコミュニケーションが取れ、チームとしての動きを意識できる方。
前向きに仕事と向き合える方。
周囲に対して気配りができる方。
【ポジションの魅力】
最新のデータ解析技術に携わり、スキルアップを図ることができます。
【開発環境】
Databricks、Azure Blob Storage、Azure Data Factory、SQL/Python、Power BI
【クラウドエンジニア(AWS)】AWSデータ確認を中心としたテスト案件
作業内容 【業務内容】
開発中のAWS環境のシステムにおいて、外部データソースとの疎通確認や前処理・分析処理の結合テストを実施し、安定稼働に向けた検証作業を行います。
【作業内容】
・AWS外部のデータソースとの疎通確認(結合テスト)
・前処理パイプライン(Step Functions、EMR、Spark)の結合テスト、サイクルテスト、シナリオテスト
・Lambdaを用いた前処理・分析処理の検証
【稼働日数】週5日
【リモート日数】週1のMTGで出社有
【Node.js/TypeScript】自動車向けデータ分析プラットフォーム開発
業務委託(フリーランス)
Node.jsSparkTypeScriptKafka
バックエンドエンジニア
作業内容 【20代~40代の方向け】
自動車の走行データを解析・提供するプラットフォームのバックエンド開発です。
Node.js(TypeScript)を使用して、データストリームの処理、分析結果のAPI化、レポート作成機能の開発を担当します。
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
【データ分析系(Python/SQL/R/BI)】データ蓄積基盤構築プロジェクのデータパイプラインの設計・構築
業務委託(フリーランス)
PythonSQLAWSGlueAthenaLambda
作業内容 Databricks on AWS 環境におけるデータ蓄積基盤構築プロジェクトにて、データパイプラインの設計・構築を担当いただきます。
データエンジニアリングの実務経験を活かし、最適なデータフロー設計と処理基盤の整備を推進できる方を募集しています。
【業務内容】
Databricks on AWS 環境でのデータパイプライン設計・構築
データ蓄積基盤の要件定義・設計支援
各種データソースからのデータ収集・加工・統合処理
性能最適化および運用性向上に向けた改善提案
【稼働日数】週5日
【リモート日数】フルリモート
【クラウドエンジニア(AWS) / リモート案件紹介可能】AWS・GCPを活用したデータ基盤整備と移行プロジェクト
業務委託(フリーランス)
AWSGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
AWSデータレイクからBigQueryへのデータ移行作業や、GCPデータ基盤の整備を行うプロジェクトです。PythonやSparkを活用し、データ基盤の設計・開発を進めるとともに、効率的なデータ処理環境を構築します。TerraformやCI/CDツールを利用した開発プロセスにも携わります。
■具体的な業務内容
・AWSデータレイク(S3 + Glue data catalog)からBigQueryへのデータ移行
・GCPデータ基盤の整備およびワークフローエンジンの導入
・PythonやSparkを使用したアプリケーション開発および保守
・TerraformやCI/CDツールを利用した開発環境の整備
・データ基盤設計および運用改善
【クラウドエンジニア(AWS) / リモート案件紹介可能】AWSおよびGCPを活用したデータ基盤整備プロジェクト
業務委託(フリーランス)
AWSGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
AWSおよびGCP環境でのデータ基盤整備プロジェクトです。データレイクからBigQueryへの移行作業や、GCPのデータ基盤整備を担当します。PythonやSparkを活用し、TerraformやCI/CDツールを使用した効率的な基盤開発を進めます。
■具体的な業務内容
・AWSのデータレイク(S3+Glue data catalog)からBigQueryへのデータ移行作業
・GCPデータ基盤の設計および整備(ワークフローエンジン導入など)
・AWS上で動作するアプリケーションの課題発見および解決
・Python、Hive、Sparkを使用したデータ基盤の構築
【Java(Spring Boot)】【業務委託(準委任)】道路交通系開発案件【リモートOK】
作業内容 【20代~30代のITエンジニアが活躍中!】
■概要
道路交通系開発をお任せいたします。
Hadoop上で動作する道路交通系システムの開発をご担当いただきます。
■作業工程:詳細設計~結合テスト
【AWS】システム開発案件
業務委託(フリーランス)
JavaPythonSQLCSSHTMLWindowsLinuxMySQLDjangoSparkFlaskAWSGitHub
データサイエンティスト
作業内容 開発、運用を繰り返すイメージです。
AWS上でのデータ解析基盤の構築
画面側はPython,html,cssなどを使います。
利用するAWSサービスの候補
- Redshift,EMR(spark),Athena,RDS,EC2,VPC,CloudFormation,Lambda,StepFunction
開発工程
基本設計, 詳細設計, 実装, 単体テスト, 結合テスト, システムテスト
【その他】データ解析・データ解析のプログラミング~DBアクセスプログラミング【リモートOK】
PythonAWSGoogle Cloud Platform
作業内容 ■概要
大手製造メーカー様案件で、データ解析・データ解析のプログラミング~DBアクセスプログラミングを担当していただきます。
※参画いただいた後は、相談の上プロジェクトの中でその他の役割も担って頂く可能性もございます。
【Python / リモート案件ご紹介可能】AWSデータ解析基盤開発(大手メーカー内バックオフィス業務)
業務委託(フリーランス)
JavaPythonSQLCSSHTMLSparkAWS
作業内容 ★エンジニア実務経験2年以上 / 直近で実務経験のある方が対象の案件です!!★
■概要
大手メーカーのバックオフィス業務を支えるデータ解析基盤の開発を担当します。AWSを活用し、RedshiftやEMR(Spark)、Athenaなどのデータ処理技術を用いたシステムを構築します。Pythonを中心としたデータ処理・分析のスキルが求められます。
■具体的な業務内容
・AWS環境上でのデータ解析基盤の設計・開発
・Pythonを用いたデータ処理スクリプトの作成
・SQLを用いたデータ抽出・集計処理の実装
・AWS Lambda、Step Functionsを活用したワークフロー構築
・Tableauを用いたデータ可視化(可能であれば対応)
【AWS / リモート案件ご紹介可能】大手自動車メーカー向けAWS基盤設計・構築
作業内容 ★エンジニア実務経験2年以上 / ブランクのない方が対象の案件です!!★
■概要
大手自動車会社のIoT基盤を支えるAWS上のサーバ基盤運用における設計・構築業務を担当するプロジェクトです。オンプレミスからクラウドに移行したシステムにおいて、AWSの各種マネージドサービスやHadoopエコシステムを活用し、安定した基盤運用を目指します。長期的な支援が見込まれるため、スキルを深める環境が整っています。
■具体的な業務内容
・AWS環境でのサーバ設計・構築業務
・運用設計の策定および運用支援
・Hadoopエコシステム(Apache Spark、Kafkaなど)を用いたデータ基盤構築
・AWSマネージドサービスの活用および最適化
【Python / リモート案件紹介可能】大規模データ活用基盤改善/データ分析基盤エンジニア
業務委託(フリーランス)
PythonSQLShellLinuxAWSDockerGitSVNGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
大手人材派遣会社における派遣領域のデータ活用基盤を対象とした改善・保守運用を担当します。レコメンドエンジンを提供するデータ基盤や分析環境の改善に加え、クラウドサービスやミドルウェアの新規技術検証、簡易的な機械学習モデルのチューニングなども手掛けます。大規模データ処理やPython、Linux環境での開発経験を活かし、データ基盤の構築に貢献できるポジションです。
■具体的な業務内容
・レコメンドエンジンを提供するデータ基盤・分析環境の改善および保守運用
・クラウドサービスやミドルウェアの新規技術検証
・簡易的な機械学習モデルのチューニングやデータ分析
・大規模データ処理基盤に関する運用業務(Hadoop, Spark, Treasure Data)
・インフラ関連ツール(Docker、CI/CD)の業務運用および保守
【Java(Spring)】某社のクレジット基幹システム内の売上処理の再構築案件
作業内容 ■概要
某社のクレジット基幹システム内の売上処理の再構築案件をお任せいたします。
■具体的な作業内容
・Host(COBOL)のシステムをオープン化(Java化)しているが、ストレートコンバージョンによる実施の為、Host特有のロジック等があり非効率なロジックが多く、無駄な処理時間がかかっている。
・ロジックを見直しながら、純粋にJavaで一から作り直すことで性能改善を図る。
・また、現状バッチ処理による一括更新だが、Kafkaを導入し、トランザクション処理化を行う。
・他担当の技術的サポート・ソースレビューなどもできる開発者を要望。
・フェーズがテストよりになるため、結合テスト/システムテストをひと通り従事したことあり、具体的にどのようなタスクかを理解している方。
・在宅勤務下であることから、コミュニケーション能力があり、各種報告等をしっかりできる方。
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
【Java(Spring)】【業務委託(準委任)】某社のクレジット基幹システム内の売上処理の再構築案件
業務委託(フリーランス)
JavaOracleSpring
作業内容 【20代~30代のITエンジニアが活躍中!】
■概要
某社のクレジット基幹システム内の売上処理の再構築案件に携わっていただきます。
■募集理由
・Host(COBOL)のシステムをオープン化(Java化)しているが、ストレートコンバージョンによる実施の為、Host特有のロジック等があり非効率なロジックが多く、無駄な処理時間がかかっている
・ロジックを見直しながら、純粋にJavaで一から作り直すことで性能改善を図る
・また、現状バッチ処理による一括更新だが、Apache Kafkaを導入し、トランザクション処理化を行う
■求める方
・他担当の技術的サポート、ソースレビューなどもできる開発者
・フェーズがテストよりになるため、結合テスト/システムテストをひと通り従事したことあり、具体的にどのようなタスクかを理解している方
・在宅勤務下であることから、コミュニケーション能力があり、各種報告等をしっかりできる方
【Python / リモート案件紹介可能】大規模データ基盤エンジニア×レコメンドエンジン運用
業務委託(フリーランス)
PythonSQLShellLinuxAWSDockerGitSVNGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
派遣業界向けの大規模データ活用基盤の改善・保守を行うプロジェクトです。レコメンドエンジンの運用や分析環境の改善、クラウド環境の技術検証を通じて、より高度なデータ分析基盤の構築に貢献します。必要に応じて、簡易的な機械学習モデルのチューニングやデータ分析業務も担当します。
■具体的な業務内容
・レコメンドエンジンを提供するデータ基盤の改善および保守運用
・AWSやGCPを活用したクラウド環境での開発および運用業務
・Python、Shell、SQLを用いたデータ処理およびスクリプト作成
・新規クラウドサービスやミドルウェアの技術検証
・簡易的な機械学習モデルのチューニングおよびデータ分析
【Python(Web開発系) / リモート案件紹介可能】AWS活用×新規プロダクト/サーバーサイドエンジニア
業務委託(フリーランス)
PythonAWS
サーバーサイドエンジニア
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
新規プロダクトのサーバーサイド開発を担当するプロジェクトです。主にAWSのリソースを活用し、API GatewayやLambdaを利用したAPI開発やGlue Jobを用いたETL処理の設計・開発を行います。プロダクトオーナーとの仕様策定やデータベース設計を担当するだけでなく、データ処理やAPIの最適化にも携わり、幅広い知識を身に付けることが可能です。
■具体的な業務内容
・RDBのデータベース設計および開発
・Glue Jobを利用したETL処理の設計・開発
・API Gateway、Lambdaを利用したAPI開発
・AWSリソースを活用したプロダクト開発の設計・実装
・技術的知見を活かしたプロダクトオーナーとの仕様策定
・Git flowをベースにした開発進行
【週5稼働可能な方にぴったり】Python/バッチ開発・運用エンジニア(フルリモート)【Python(データ分析系)】
業務委託(フリーランス)
PythonGoogle Cloud Platform
作業内容 【20 代から40 代の方が活躍中!】
※週4日〜OK案件です!
※実務経験2年以上ありの方が対象の案件です!
■概要
独自のデータ集積プラットフォームを運営する企業での、DBバッチ開発および運用業務です。Pythonを使用したバッチ開発や、データのインサート作業を行います。Google Cloud Platform(GCP)環境下で、5名のチーム体制でデータ処理を手掛けます。
■具体的な業務内容
・Pythonを用いたバッチ開発、改修、運用
・データインサート業務
・GCP環境でのデータ処理(BigQuery、Cloud Composerなど)
・データの高速化や自動化対応
勤務開始時には、プロジェクトの一員として、コミュニケーションを取りながら業務を進めて頂く予定です。また、緊急時に出社が必要となる場合がございます。
------------------------------------------------------------------
直近の参画案件の経験とご希望に併せた案件のご紹介をさせて頂きます。
弊社は様々なプロジェクトの提案を強みとしておりますので、お気軽にご相談頂けますと幸いです。
------------------------------------------------------------------
※弊社では、法人、請負いの案件は取り扱っておりません。
【Python(Web開発系)】Python/バッチ開発・運用(フルリモート)
業務委託(フリーランス)
PythonGoogle Cloud Platform
作業内容 【20 代から40 代の方が活躍中!】
※週4日〜OK案件です!
※実務経験2年以上ありの方が対象の案件です!
■概要
自社のデータ集積プラットフォームを運営する企業にて、Pythonを使用したバッチ開発・運用を担当します。世界中の特許や論文データなどを扱い、データの高速処理や自動化を行うプロジェクトに参画します。リモートでの作業となります。
■具体的な業務内容
・Pythonを使用したバッチ開発および改修
・データベースへのデータインサート
・GCP環境でのシステム開発および運用
・データ処理の高速化および自動化対応
勤務開始時には、プロジェクトの一員として、コミュニケーションを取りながら業務を進めて頂く予定です。また、緊急時に出社が必要となる場合がございます。
------------------------------------------------------------------
直近の参画案件の経験とご希望に併せた案件のご紹介をさせて頂きます。
弊社は様々なプロジェクトの提案を強みとしておりますので、お気軽にご相談頂けますと幸いです。
------------------------------------------------------------------
※弊社では、法人、請負いの案件は取り扱っておりません。
【Python / リモート案件紹介可能】レコメンドエンジン|モデル開発・改善プロジェクト
業務委託(フリーランス)
PythonSQLShellLinuxGitSVN
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
大手クライアントの派遣事業におけるレコメンドエンジンの改善および新規開発を担当するプロジェクトです。開発系ではデータ加工やWebAPI開発、分析系では機械学習モデルの構築やチューニングなどを担当いただきます。Python、Shell、SQLを用いた開発または分析経験が求められます。クラウド環境や大規模データ処理に興味がある方も歓迎します。
■具体的な業務内容
開発系:
・データ加工、バッチ開発、WebAPI開発、新規技術の検証
・Linux環境における開発およびドキュメント作成(設計書、テスト仕様書)
分析系:
・基礎分析、機械学習モデル構築、チューニング、レポーティング
・データ加工および検証作業
【データエンジニア/英語】パイプライン設計実装案件
業務委託(フリーランス)
PythonSQLSparkAWS
データサイエンティスト
作業内容 ・パイプライン設計実装案件に携わっていただきます。
・主に下記作業をご担当いただきます。
- パイプラインの設計、実装
- データ品質チェックの実装
- システム間reconciliationロジックの実装
【データサイエンティスト】リテール企業向けデータ分析案件
業務委託(フリーランス)
PythonSQLRSparkAzureJIRATableau
データサイエンティストサーバーサイドエンジニア
作業内容 ・リテール業界向けにクライアント課題を解決するソリューションの基盤となるデータ分析やモデル構築をご担当いただきます。
・主に下記作業をご担当いただきます。
-要件に基づいたデータ分析
-機械学習モデルの構築
-非機能的な視点での分析や提案および改善
-データの前処理やクリーニング
-高トラフィック時におけるデータ処理のサポート
-クラウドアーキテクトチームと協働し、新しいソリューションを作成
【Python/SQL/リモート併用/週5日】クラウドデータ基盤構築エンジニア
業務委託(フリーランス)
PythonSQLSparkAWSAzureGoogle Cloud PlatformRedshiftBigQuery
作業内容 要件定義,基本設計,詳細設計,実装,テスト,運用・保守
企業のマーケティングDXや事業変革をデータ活用で支援するコンサルティングファームにて、データ基盤(DWH・ETL・データレイク)の設計・構築を担当いただきます。
東証プライム上場企業を中心とした大手クライアントに対し、データドリブン経営の核となる基盤づくりをリードするポジションです。
具体的には、Snowflake、BigQuery、Databricksといった最新のクラウドDWHの導入支援や、Python/SQLを用いた効率的なデータパイプライン(ETL/ELT)の設計・実装に携わっていただきます。
また、ストリーミングデータ処理やデータガバナンス設計など、大規模かつ複雑なデータ環境において最適なアーキテクチャを提案・構築していただくことを期待しています。
BI・分析チームと密に連携しながら、ビジネス価値を生むためのデータ提供基盤を、最先端の技術スタックを用いて実現できるやりがいのある環境です。
【リモート併用】官公庁向け電力データ集約システム/アーキテクト(AWS×Databricks) No.25502
作業内容 【概要】
既存電力データ集約システムのアーキテクチャ維持および改善、
AWS・Databricks を活用したデータレイク/ETL基盤の設計見直しなどを担当いただきます。
現時点では構築フェーズではなく、不具合対応・パイプライン設計の見直しなど既存システムのお守りが中心となります。
本格的な構築は 7月-または10月-を予定。
Snowflakeなどデータ基盤の経験がある方はイメージしやすい業務です。
【業務内容】
具体的な業務は以下となります。
・AWS×Databricks のデータパイプラインの設計見直し
・既存Spark/ETLフローの調査と改善
・不具合発生時の原因調査とアーキ再設計
・データレイクの構造改善/最適化
・コードアーキテクチャ(Git)レビュー
・データワークフローの最適化
・将来のBigQuery連携に向けた設計検討
【工程】
現行調査(アーキ・パイプライン)
要件定義(構築フェーズ以降)
基本設計(アーキ構成/データレイク)
詳細設計(パイプライン)
セキュリティ/ネットワーク設計
性能設計
不具合時のアーキレビュー
最適化提案
監査対応を見据えた設計
【体制】
調査-参画中のプロパー:2名+今回のポジション
他、library管理者1名、アーキテクチャ1名
保守チームのプロパー:2名
【リモート/出社】
リモート勤務との併用が可能です。
週1日程度、豊洲にあるデータセンターへの出社対応があります。
【PC】貸与あり
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
【Python/SQL/リモート併用/週5日】全社データ分析基盤のアーキテクチャ設計・構築支援
業務委託(フリーランス)
PythonSQLSparkAWSApacheGitHubGoogle Cloud PlatformRedshiftBigQueryTerraform
AIエンジニアサーバーサイドエンジニア機械学習エンジニアバックエンドエンジニア
作業内容 基本設計,詳細設計,実装,テスト,運用・保守
大手インターネット企業にて、全社データ分析基盤のアーキテクチャ設計および構築をMLエンジニアとして担当していただきます。
主な業務は、数千万〜数億レコード規模の大規模データを扱うデータレイクやDWH(BigQuery)の設計・運用です。
具体的には、OCIからGCPへのクロスクラウドデータ連携の実装や、ETL/ELTパイプラインの開発、Terraformを用いたIaCによるインフラ管理を担っていただきます。
また、AIデータアクセス基盤(MCP/Agent)の構築や、データガバナンス・セキュリティ設計(IAM/VPC)など、最先端のデータ基盤構築に幅広く携わることができる環境です。
【フルリモート】申し込み及び各種情報確認ポータルにおけるフルスタック開発(週5日 / Go)
業務委託(フリーランス)
JavaPythonAWSGitGitHub
フルスタックエンジニアバックエンドエンジニア
作業内容 社内外に公開しているAPIの開発などをフルスタックに対応いただきます。
========================
※必ずお読みください※
【20 代から50代前半の方が活躍中】
※実務経験1年以上ありの方が対象の案件です!
【外国籍の方の場合】
日本語能力検定1級お持ちの方
日本語が母国語の方
※日本在住の方のみ
========================
【データエンジニア】某SNS企業向け開発支援案件
業務委託(フリーランス)
PythonSQLApache
作業内容 ・某SNS企業におけるデータ基盤の全工程を完結させる自律体制の構築に携わっていただきます。
・主に下記作業をご担当いただきます。
- データパイプラインの構築・実装
- 既存データパイプラインの運用保守・監視
- Hadoop基盤の整備・改善
- 技術移転・ドキュメント化
【データエンジニア】全社データ基盤アーキテクチャ設計構築支援案件
作業内容 ・全社データ分析基盤のアーキテクチャ設計・構築に携わっていただきます。
・主に下記作業をご担当いただきます。
- データレイク / DWH(BigQuery)基盤の設計・運用
- ETL / ELTパイプラインの設計・開発
- クロスクラウドデータ連携(OCI → GCP)の設計・実装
- データモデリング(OBT / mart)の設計
- Terraformを用いたIaCによるインフラ管理
- データ基盤に関わるネットワーク・セキュリティ設計(IAM / VPC / データガバナンス)
- AIデータアクセス基盤(MCP / Agent)の構築
【リモート併用/週4相談可能/AWS×Databricks】官公庁向け電力データ集約システム/Databricks Library 管理エンジニア No.25501
業務委託(フリーランス)
PythonAWSGitJP1
ネットワークエンジニア
作業内容 【概要】
AWS上に構築されたデータレイクおよび Databricks 環境における、
Pythonライブラリ・証明書・ETL関連コンポーネントのバージョン管理・更新作業を担当いただきます。
既存Library やデータレイクに対するアップデートを中心とした業務で、4‐9月は現行システム(ステップ4)の維持保守と引継ぎ期間となります。
【業務内容】
具体的な業務は以下となります。
・Library(Python・Driver など)のバージョン管理
・Databricks上のETL環境に伴うLibrary更新作業
・AWS上のデータレイク環境における構成管理
・証明書更新(Peakload含む)
・個別で実装されているコンポーネントの確認・管理
・Gitを利用したコード管理
・既存環境の棚卸し・ドキュメント整備
【工程】
現行調査
バージョン管理
依存関係管理
脆弱性確認
変更手順の作成
検証(単体/結合)
Libraryリリース
証明書更新(Peakload含む)
ドキュメント整備
【体制】
調査-参画中のプロパー:2名+今回のポジション
他、library管理者1名、アーキテクチャ1名
保守チームのプロパー:2名
【リモート/出社対応】
リモート勤務との併用が可能です。
週1日程度、豊洲にあるデータセンターへの出社対応があります。
【PC】貸与あり
(リモート)データ利活用を目的としたビッグデータの加工、集計業務【AWS】
業務委託(フリーランス)
PythonSQLLinuxAWSLambda
インフラエンジニア
作業内容 スクラムのメンバーとして、基盤構築/アプリ開発を業務としてご担当していただきます。
【Java/JavaScript】《建築会社向け》会計パッケージの開発、保守(リモート)
業務委託(フリーランス)
JavaJavaScriptHTMLDynamoDBCassandraSpringSparkAngularAWSApacheAuroraElasticsearch
バックエンドエンジニア
作業内容 ・基本設計~結合テスト、保守をご担当
・フロント:Javascript、Angular、HTML
・サーバー:Java8、Spring Boot、Elasticsearch、Apache Spark
・DB:AWS Aurora、AWS DynamoDB、Apache Cassandra
・インフラ:AWS EC2、S3、EBS、ElastiCache
Saasプロダクトデータ基盤構築【Python(リモート)】
業務委託(フリーランス)
PythonSQLSparkAWSDocker
バックエンドエンジニア
作業内容 ・在庫最適化システムを支えるデータ基盤の構築を行っていただきます。
・顧客からの数億レコードにもなる大量データの加工をSQLやPythonを用いて作成し、集計後、データストアに投入する機構の構築に携わっていただきます。
【開発環境】
・開発言語:Python、SQL
・DB:Aurora(PostgreSQL互換)、Redshift
・ライブラリフレームワーク:Pandas、Numpy、Dask
・インフラ:AWS
・AWS製品:ECS、S3、Step Functions、Lambda、CloudWatch
・環境、ツール:Docker、GitHub、Jira、Slack、CircleCI、Sentry
【JavaScript/React】配信入稿管理システム開発案件
業務委託(フリーランス)
JavaScriptReact
フロントエンドエンジニア
作業内容 ・配信入稿管理システムの開発に携わっていただきます。
【DWH/データレイク】製造小売業向けDWH開発業務案件
業務委託(フリーランス)
PythonSQLShellSparkAWSGlueAthena
データサイエンティスト
作業内容 ・大製造小売業におけるデータ設計開発作業に携わっていただきます。
・主に下記作業をご担当いただきます。
- DWHやデータレイクの設計や構築、運用
- ETLやデータパイプラインの開発や改善
-分析向けデータモデルの設計および dbt を用いたモデル開発
- データ処理の品質管理やパフォーマンス改善、運用フローの最適化
- 運用チームのタスク管理やトラブルシューティング
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。