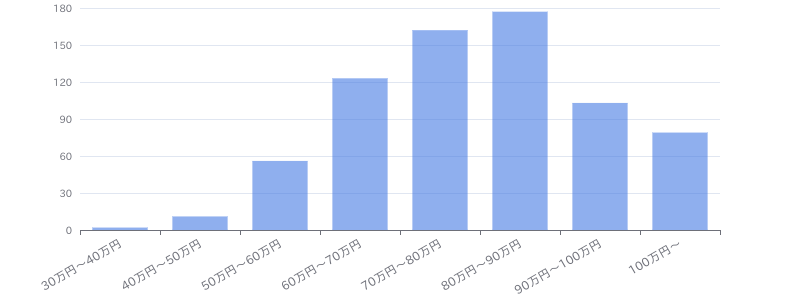
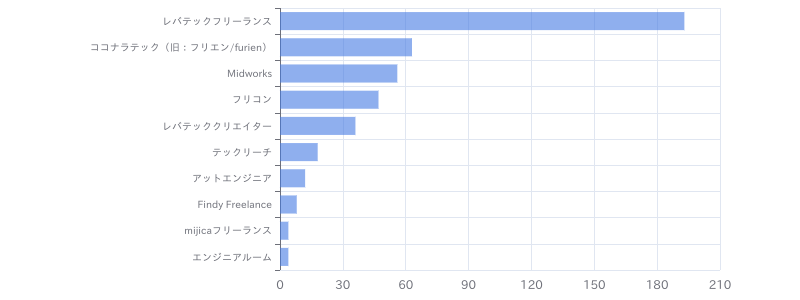
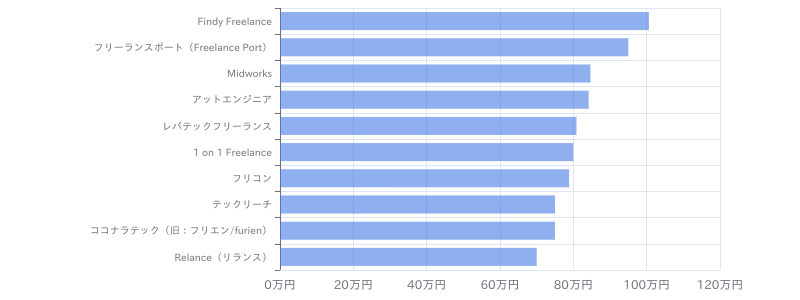
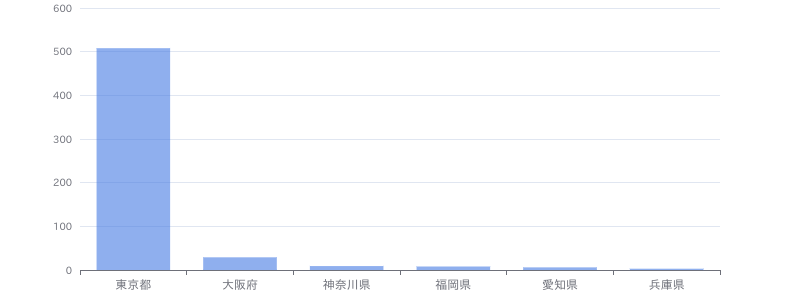
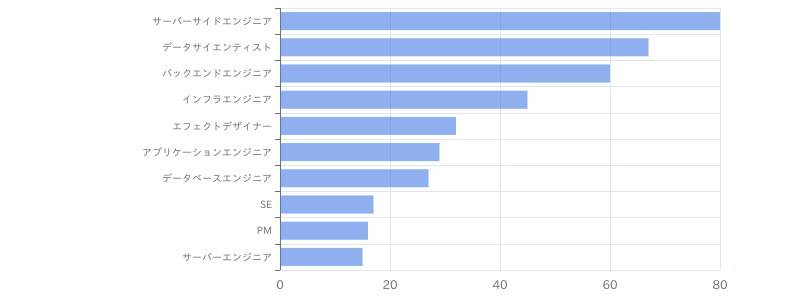
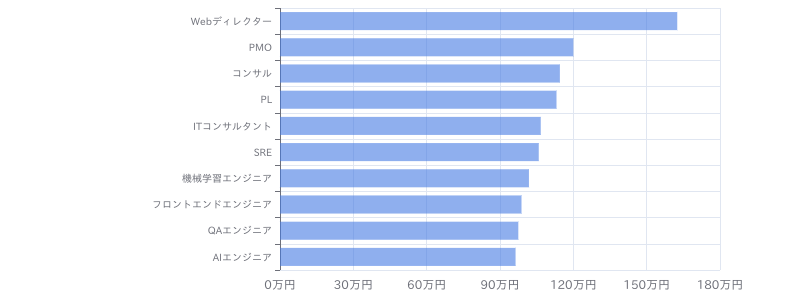
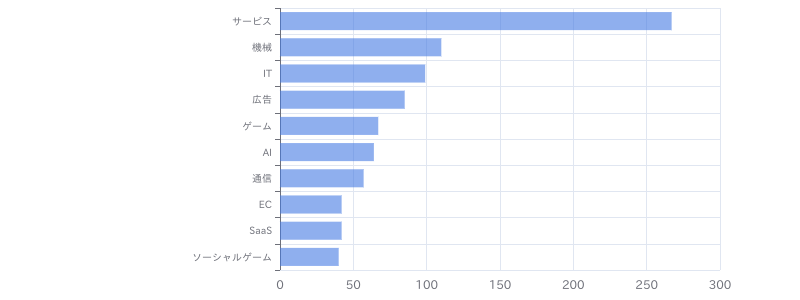
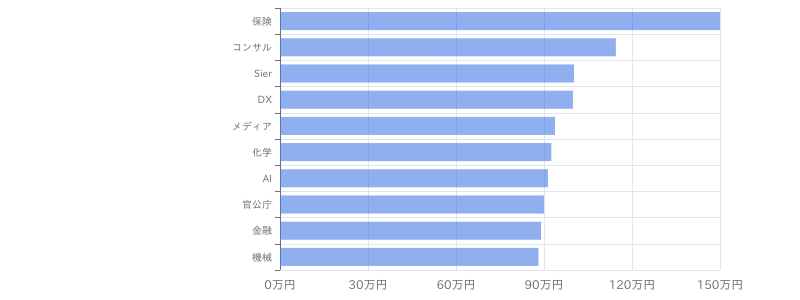
【Python(Web開発系)】学習支援サービス向けデータ分析基盤保守開発
業務委託(フリーランス)
PythonSQLSparkAzureApache
作業内容 【業務内容】
小中学生向け学習支援サービスのデータ分析基盤において、既存システムの理解と機能把握を行いながら、保守対応や機能追加開発を実施します。クラウドサービスやSQL、Python(PySpark)、Apache Sparkを活用して安定的な分析基盤運用と開発を担当します。
【作業内容】
・既存システムのソースコード、設計書、ドキュメントをもとにシステムの動作を理解
・Azure Data Factoryを用いたデータパイプラインの保守・開発
・Azure Data Lake Storageへのデータ格納、管理、処理
・Azure Databricksを用いたデータ分析処理の開発・保守
・SQLを用いたデータクエリ・加工
・Python(PySpark)とApache Sparkを用いたバッチ処理、データ変換、分析処理
エフェクトデザイナー/SPARK GEAR・Unity/ゲーム開発
業務委託(フリーランス)
SparkUnity
3Dデザイナーエフェクトデザイナー
作業内容 <<スマホゲームを中心に、「ゲームで世界に感動を創り出す」企業!!>>
ゲーム開発におけるエフェクトデザイナー業務をお任せします。
■□具体的には…□■
・バトルキャラクター、モンスターのエフェクトデザイン制作
・シナリオキャラクターのエフェクトデザインの制作
・エフェクト演出制作
・組み込み、実装
・使用ツール
∟SPARK GEAR/Unity/Photoshop/Maya
<こんな方におすすめです!>
・デザインスキルを活かしたい方
・新しい技術や表現に挑戦したい方
【DBエンジニア(SQL全般)】データ加工基盤刷新データベース開発
作業内容 【業務内容】
大手SIer向けに老朽化したデータ加工基盤の刷新を目的とし、ApacheSparkで構築された既存システムをDatabricksへ移行する業務です。EOSL対応の一環として、データ加工処理基盤のマイグレーションを推進し、Databricksを活用した新たな開発標準の策定と現場への導入を行います。移行計画の立案から実行管理、チームリードまでを担い、安定したデータ基盤の再構築と運用性向上を実現します。
【作業内容】
・ApacheSparkで記述された既存データ加工処理のDatabricks移行
・Databricks向け開発標準の策定と導入
・移行作業全体の計画立案と実行管理
・プロジェクト進捗管理と課題解決
・メンバーへの作業指示とチームリード
(リモート)【Python、SQL】メーカー向けデータ利活用支援
業務委託(フリーランス)
PythonSQLAWSRedshiftGlue
バックエンドエンジニア
作業内容 ・python(実行はRedshift)からSparkSQLへの移行案件
・SparkSQLの移行実装は終えているが、不具合が発生しているためその修正及び試験を実施
・環 境:AWSGlue/Redshift/SparkSQL/python
-SQL実装経験(サブクエリ・外部結合を構築可能)
【DBエンジニア(SQL全般)】電力データ管理システムのクラウド移行と刷新
作業内容 【業務内容】
電力会社向けのロードカーブ作成システムの刷新を担当します。スマートメーターや子局からの計測値を用いて既存システムをクラウド環境へ移行し、計算ライブラリをSparkからSnowflakeに変更してシステムの性能向上を図ります。
【作業内容】
・既存システムのSnowflake化対応
・クラウド環境へのシステム移行
・ロードカーブ作成システムの設計・構築
・計算ライブラリの変更作業
・オンプレミス環境からクラウド環境へのデータ移行
【Python(Web開発系)】既存システムのETL処理改善プロジェクト
業務委託(フリーランス)
PythonMySQLMongoDBSparkAWSJIRARedshiftKafkaLambda
作業内容 【案件概要】
大規模データ処理基盤の構築および既存システムのETL処理改善を行うプロジェクトです。
Pythonを用いたETL開発チームのリーダーとして、要件定義からテストまで幅広い工程を担当します。
SparkやKinesisなどを活用したデータ処理基盤の構築に携わります。
AWS環境での開発を前提とし、アジャイル開発手法でプロジェクトを進めます。
【作業内容】
・ETL処理の詳細設計および設計内容の整理
・Pythonを用いたETL処理のコーディング
・ワークフローシナリオの実装
・単体テスト観点作成およびテストスクリプト作成、実施
・必要に応じたシミュレーターやスタブの開発
【サーバー(Linux系)】医療ビッグデータプラットフォーム構築
業務委託(フリーランス)
SQLLinuxPostgreSQLSparkAWSRedshiftGlueAurora
PL
作業内容 【業務内容】
医療ビッグデータを活用したデータプラットフォーム構築において、プロジェクトリーダーとしてAWS環境での設計、構築、移行、運用を担当します。システム化構想や要件定義から参画し、データベース設計やステークホルダーとの合意形成、ベンダー管理、運用準備まで幅広く携わります。
【作業内容】
・システム化構想や要件定義からのプロジェクト立ち上げ参画
・Redshift、Aurora PostgreSQL、S3、Spark等を用いたデータベース物理設計
・医療データのデータカタログ設計、抽出設計、実データ調査を含む論理設計
・プロジェクトメンバーやベンダー、データ提供元との合意形成
・フェーズレビュー支援(ゲートレビューによる品質確認)
・ベンダーコントロール(設計レビュー、成果物レビュー、受入テスト実施)
・Shell、PowerShell、Pythonを用いた設計作業
・運用準備(運用手順書作成、社内勉強会実施、関係者調整)
【Java(その他FW)】カード基幹系システム向けデータ中継システムの刷新プロジェクト
業務委託(フリーランス)
JavaWindowsLinux
作業内容 【案件概要】
クレジットカードシステムおよび加盟店データ中継システムの刷新プロジェクトです。
ホストシステムからHadoop基盤への移行により、大規模データ処理の高速化と効率化を図ります。
カードデータの分析基盤を構築し、安定性と拡張性の向上を目指します。
最新技術を活用し、安全性と信頼性を備えた基幹システムの再構築を推進します。
【作業内容】
・Javaを用いた基本設計および詳細設計
・Hadoop(HDFS、Hive)を活用したデータ中継システムの設計開発
・ホストシステムからのデータ移行プログラム開発
・Sparkを用いたデータ処理プログラム開発
・Parquet形式でのデータ保存設計および管理
・各種テストの実施および本番リリース支援
SE/PG募集(Java/TypeScript/Python/Azure)
業務委託(フリーランス)
JavaPythonSparkAzureDockerTypeScript
PGSE
作業内容 フルリモート環境にて、仕様書を基に主体的に開発(コーディング)を行っていただきます。
仕様が不明瞭な箇所については、課題管理表・チャット等でクライアントへの確認が発生します。
【Python/AWS】金融機関向けDWH開発業務支援(Python/databricks)
業務委託(フリーランス)
PythonSQLSASSparkAWSAzureApacheBigQuery
バックエンドエンジニア
作業内容 ・新規データを取りこむジョブの追加開発・テスト(取り込み処理は既存流用)
・既存パイプラインの保守、運用
・開発環境:Python、databricks、SQL、Apache Spark、Google BigQuery、SAS、SAS Viya、AWS、Azure、GoogleCloud
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
【データサイエンティスト】リテール企業向けデータ分析案件
業務委託(フリーランス)
PythonSQLRSparkAzureJIRATableau
データサイエンティストサーバーサイドエンジニア
作業内容 ・リテール業界向けにクライアント課題を解決するソリューションの基盤となるデータ分析やモデル構築をご担当いただきます。
・主に下記作業をご担当いただきます。
-要件に基づいたデータ分析
-機械学習モデルの構築
-非機能的な視点での分析や提案および改善
-データの前処理やクリーニング
-高トラフィック時におけるデータ処理のサポート
-クラウドアーキテクトチームと協働し、新しいソリューションを作成
【Python(Web開発系)】流通業向けAPI開発とAWS環境構築
業務委託(フリーランス)
JavaPythonAWSSpringBoot
作業内容 【業務内容】
流通業向けアプリケーションの開発を担当し、既存システムの機能拡張や改善を行います。JavaとSpringBootを用いたAPI開発や、AWS環境でのWorkspaces自動構築およびネットワーク設定変更を通じてシステム運用を支援します。
【作業内容】
・JavaとSpringBootを用いたREST APIの設計、開発、テスト
・AmazonWorkspacesの自動構築スクリプト作成と実行
・AWS環境でのネットワーク設定変更
【クラウドエンジニア(その他クラウド)】データウェアハウス移行と基盤構築
作業内容 【業務内容】
既存のデータウェアハウスから新しいクラウド基盤へのデータ移行と構築を担当します。Azure Data Factoryを用いたデータ統合・変換処理の設計や実装、移行作業に伴う検証やテスト工程にも携わります。
【作業内容】
・既存データウェアハウスからAzure Data Factoryへのデータ移行
・Azure Data Factoryを用いたデータ変換処理の設計・実装
・SQLを用いたデータ抽出・加工
・各種システムとのデータ連携テスト
【Java(Spring)】メガバンク向けAMLパッケージのカスタマイズ開発
作業内容 【案件概要】
海外ベンダー製AMLパッケージをメガバンク向けにカスタマイズするプロジェクトです。
海外ベンダーの日本進出に伴う案件で、他の日系金融機関への導入実績もあり今後の拡大が見込まれます。
参画前に2ヶ月間の英語オンライン研修を受講いただき、プロジェクト理解を深めてから参画いただきます。
金融機関の本番データを扱うため、東京駅近辺の客先常駐にて業務を行います。
【作業内容】
・AMLパッケージのカスタマイズ設計および開発
・Java(Spring)を用いた機能改修および追加開発
・海外ベンダーとの仕様確認および調整
・各種テスト対応および不具合修正
・ドキュメント作成および導入支援
【Java(その他FW)】会計システムの機能開発および運用保守
業務委託(フリーランス)
JavaJavaScriptHTMLSpringAngularAWS
作業内容 【業務内容】
会計システムにおける機能開発および運用保守業務をご担当いただきます。既存システムの機能拡張や不具合修正を行いながら、安定したサービス提供を支えます。バックエンドおよびフロントエンドの開発に加え、データベース設計やインフラ構築運用にも携わり、システム全体の品質向上に貢献していただきます。また、大規模データ処理を考慮した設計および開発を行い、パフォーマンス向上にも取り組みます。
【作業内容】
・バックエンド開発
・フロントエンド開発
・データベース設計
・データベース開発
・インフラ構築
・インフラ運用
・パイプライン構築
・パイプライン運用
・結合テスト
・保守対応
【データエンジニア】某SNS企業向け開発支援案件
業務委託(フリーランス)
PythonSQLApache
作業内容 ・某SNS企業におけるデータ基盤の全工程を完結させる自律体制の構築に携わっていただきます。
・主に下記作業をご担当いただきます。
- データパイプラインの構築・実装
- 既存データパイプラインの運用保守・監視
- Hadoop基盤の整備・改善
- 技術移転・ドキュメント化
【Python(Web開発系)】道路マネジメントプラットフォームのバックエンド・データ基盤開発支援
業務委託(フリーランス)
JavaPythonSQLNode.jsGit
バックエンドエンジニア
作業内容 【案件概要】
道路マネジメントプラットフォームの構築フェーズにおけるバックエンドおよびデータ基盤開発案件です。
データ志向のシステム設計を前提に、複数データの統合およびモデリングを行います。
社内外システムとの連携を含めたプラットフォーム全体の設計・開発に携わっていただきます。
大量データを扱うデータ基盤の構築を推進するポジションです。
【作業内容】
・Python、Java、Node.jsいずれかを用いたバックエンド開発
・REST APIの設計および開発
・SQLおよびRDBを用いたデータ操作および設計
・ETLおよびデータパイプラインの設計および構築
・大量データ処理およびパフォーマンス改善
・Gitを用いたチーム開発対応
(リモート)データ分析ツールの導入・開発保守【Python】
業務委託(フリーランス)
Python
バックエンドエンジニア
作業内容 ・データ分析、利活用ツールの導入、保守開発等(開発より調査やドキュメント作成の方が多い想定)
・Azureへの移行
(リモート)【Java】カード基幹系システム オープン系開発
業務委託(フリーランス)
JavaCOBOLWindowsLinuxHiveGitlabVSCode
バックエンドエンジニア
作業内容 ・カード基幹系システム開発
・現行システム(COBOL)から新システムへのマイグレーション開発(ホスト→Hadoop基盤へのデータ連携)
・工程:基本設計、詳細設計、製造、テスト、本番リリース、運用/保守
(リモート)エンタメSaaSサービスにおけるデータエンジニア
業務委託(フリーランス)
JavaPythonSQLAWSGoogle Cloud PlatformBigQueryGlueTerraform
作業内容 現在、AWS(データレイク)とGCP(DWH)を組み合わせたハイブリッドクラウド基盤を構築中です。
この基盤をスケールさせ、俊敏なデータ活用を全社に浸透させるために、AWSGlue や BigQueryを活用したデータパイプライン開発を担当いただくデータエンジニアを募集します。
サービス運営・ビジネス分析・出版社支援など多様な活用ニーズに応えるためのデータ基盤構築をお任せします。
▪️データレイク/ETL 基盤の構築
・AWS Glue(Apache Spark)による分散処理・ETL 開発
・S3/Lake Formation を用いたデータ管理・セキュリティ設計
▪️BigQuery ベースの DWH 環境整備
・AWS → GCP 間データ連携パイプラインの最適化
・BigQuery によるデータモデリング・クエリ最適化
▪️IaC を軸としたマルチクラウド管理
・Terraform による環境差分管理・自動化
▪️品質管理・運用効率化
・Airflow などのワークフロー管理と CI/CD 整備
・データ品質テストの自動化
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
(リモート)データ利活用を目的としたビッグデータの加工、集計業務【AWS】
業務委託(フリーランス)
PythonSQLLinuxAWSLambda
インフラエンジニア
作業内容 スクラムのメンバーとして、基盤構築/アプリ開発を業務としてご担当していただきます。
【データ分析系(Python/SQL/R/BI)】大手企業向けデータ分析基盤開発支援
業務委託(フリーランス)
PythonSQLGoScalaSpark
作業内容 【案件概要】
・大手企業向けデータ分析基盤およびETL基盤のシステム開発支援。
・データ活用を目的としたアーキテクチャ検討から設計・実装までを担当。
・ビッグデータ分析・加工のための分散処理基盤を構築。
・Python/SQL/クラウド基盤/BIなどを活用したデータエンジニアリング業務。
【作業内容】
・データ分析基盤/ETL基盤におけるアーキテクチャ検討(要件整理、方式検討、ツール選定)
・データレイク/DWH/マート構成の設計(スキーマ設計、パイプライン構成、データフロー設計)
・Python/SQLを用いたETL処理の実装(データ抽出、加工、統合、ロード処理の自動化)
・分散処理基盤(Spark、Hadoop、クラウドネイティブ基盤等)の構築・パフォーマンス最適化
・各種データパイプラインのジョブ設計・バッチ開発
・データ品質管理(クレンジング、検証ロジック実装、異常検知処理の整備)
・BIツール向けデータマートの整備、レポート用データセット設計
・基盤運用に向けたドキュメント作成(設計書、データフロー図、運用手順書など)
【開発環境】
・OS(インフラ)/クラウド(GCP、IaaS、PaaS、FaaS)、Spark、Kubernetes、Linux
・DB/Cassandra、Redis、Elasticsearch、mySQL、PostgreSQL
・ツール/JIRA、Confluence、GitLab、Slack、GoogleWorkspace
・運用/IaC(Terraform、Ansible、Helm)、CI/CD(GitLabCI、kubectl)
【Databricks/PySpark/Azure】商用車ロジスティクス可視化基盤のデータ処理最適化
業務委託(フリーランス)
ScalaSparkAzure
サーバーエンジニア
作業内容 【作業内容】
・Databricks(PySpark, Scala)環境のパフォーマンス最適化を行います。
・大規模データ処理の実装・改修を担当します。
・Azureデータ基盤のパフォーマンス改善を行います。
・保守・構成管理およびリファクタリングを担当します。
【Java/TypeScript/Python/フルリモ】官公庁向け情報管理システムPoC開発
業務委託(フリーランス)
JavaPythonSparkAzureDockerTypeScript
サーバーサイドエンジニア
作業内容 【作業内容】
来年度の本番開発に向けて、主な機能を構築してPoC実施するプロジェクトの開発部分を担当しています。
DBより情報を抽出して、帳票(Excel)出力する機能の開発を行います。また、既存仕様書をもとに自立的に開発・実装を推進し、コンテナ環境やクラウドサービスを活用したシステム構築を行います。
データ基盤やアプリケーションの品質担保や課題解決も担当していただきます。
開発(コーディング)を中心に進行します。
※仕様書上不明瞭な部分があるため、課題管理表やチャットなどを中心にクライアントの確認程度は発生することがあります。
【求める人物像】
・仕様書を読み解き、主体的にタスクを進められる方
・問題解決力が高い方
・コミュニケーション能力があり、チーム連携を重視できる方
【Databricks/SQL/Python/フルリモート】データ解析システム構築支援案件
業務委託(フリーランス)
PythonSQLHadoopSparkApacheGitKafka
サーバーサイドエンジニア
作業内容 【募集背景】
【作業内容】
Databricksによるデータ解析システムの構築支援(設計/実装/テスト)を行います。
【求める人物像】
受け身や指示待ちでなく、主体的に業務に取り組み積極的に行動できる方。
チームメンバーとも積極的にコミュニケーションが取れ、チームとしての動きを意識できる方。
前向きに仕事と向き合える方。
周囲に対して気配りができる方。
【ポジションの魅力】
最新のデータ解析技術に携わり、スキルアップを図ることができます。
【開発環境】
Databricks、Azure Blob Storage、Azure Data Factory、SQL/Python、Power BI
【クラウドエンジニア(AWS)】AWSデータ確認を中心としたテスト案件
作業内容 【業務内容】
開発中のAWS環境のシステムにおいて、外部データソースとの疎通確認や前処理・分析処理の結合テストを実施し、安定稼働に向けた検証作業を行います。
【作業内容】
・AWS外部のデータソースとの疎通確認(結合テスト)
・前処理パイプライン(Step Functions、EMR、Spark)の結合テスト、サイクルテスト、シナリオテスト
・Lambdaを用いた前処理・分析処理の検証
【稼働日数】週5日
【リモート日数】週1のMTGで出社有
【データ分析系(Python/SQL/R/BI)】データ蓄積基盤構築プロジェクのデータパイプラインの設計・構築
業務委託(フリーランス)
PythonSQLAWSGlueAthenaLambda
作業内容 Databricks on AWS 環境におけるデータ蓄積基盤構築プロジェクトにて、データパイプラインの設計・構築を担当いただきます。
データエンジニアリングの実務経験を活かし、最適なデータフロー設計と処理基盤の整備を推進できる方を募集しています。
【業務内容】
Databricks on AWS 環境でのデータパイプライン設計・構築
データ蓄積基盤の要件定義・設計支援
各種データソースからのデータ収集・加工・統合処理
性能最適化および運用性向上に向けた改善提案
【稼働日数】週5日
【リモート日数】フルリモート
【Python(Web開発系)】設備事業向け統合データ基盤の構築プロジェクト
作業内容 【案件概要】
既存のTableau環境に対し、Databricksを追加採用し、社内外データを一元的かつ効率的に管理する統合データ基盤を構築するプロジェクトです。
現状はTableauのみが導入されており、分析基盤の拡張およびデータ活用高度化が課題となっています。
Databricksを中核としたデータ基盤を新たに構築し、データレイクとDWH(データウェアハウス)を統合します。
あわせて、周辺のデータ準備処理やワークフローを整備し、持続的に運用可能なBI基盤の実現を目指します。
【作業内容】
・Databricksを活用したデータ基盤環境の設計および構築
・データレイクおよびDWHの統合設計
・Pythonを用いたデータパイプラインの設計および構築
・データ準備処理およびワークフローの整備
・既存Tableau環境と連携したデータ活用基盤の構築
【サーバー(Windows/系)】インターネット企業向け新規DWH構築プロジェクト
業務委託(フリーランス)
WindowsBigQuery
作業内容 【案件概要】
大手インターネット企業にて、社内に点在する各種データを一元管理するための新規DWH構築プロジェクトです。
データ取り込みから加工・集約までを担う基盤を整備し、全社的なデータ活用を支える役割を担います。
BigQueryおよびApache Airflowを活用し、データパイプラインの設計・開発・運用改善までを一貫して対応します。
Google系およびオープンソース技術を組み合わせながら、拡張性と運用性を意識したデータ基盤構築を進める想定です。
【作業内容】
・新規DWH構築に向けた全体アーキテクチャ設計
・BigQueryを用いたDWH設計およびテーブル設計
・Airflowによるデータ取り込み/加工パイプラインの設計および実装
・各種データソースからのデータ連携、加工、集約処理
・データパイプラインの運用設計および改善対応
・性能や安定性を考慮したチューニングおよび最適化
・関係部署との要件調整および技術的な検討支援
【技術環境】
・DWH/分析基盤:BigQuery
・ストレージ:Google Cloud Storage(GCS)
・データ形式:Parquet
・データ処理:Spark
・実行コンテナ:Google Kubernetes Engine(GKE)
・パイプライン制御:Airflow
・連携(ストリーミング/CDC):Kafka, Debezium
【備考】
・PC貸与:無し(ご自身のPCからVDIで作業。PCのOSやスペック不問)
・本エンドに弊社から10名以上参画中(本PJにも3名参画中)
【Python/フルリモート】薬局向けアプリケーション開発エンジニアの案件・求人
作業内容 薬局経営を支援する薬局ダッシュボードの画面・機能開発する責務を担っていただきます。
現状の薬局経営は、経営者による意思決定の質のばらつき、現場薬剤師に適切な説明責任を果たすことができない、分析にコストがかかるなどの課題が存在しています。
このダッシュボードは、薬局経営のオーナーや現場薬剤師に対して、薬歴業務・収益・患者関係性の項目を可視化することで、薬局経営の日々の業務改善の意思決定をサポートするサービスとなります。
(開発環境)
・React、Next
・TypeScript
・AWS(Cognito、Amplify、API Gateway、Lambda、RDS、S3)
・Python
・その他(GitHub、Datadog、Google Analytics、GTM、KARTE)
※当案件におきましては、直近参画期間が半年以内の案件が続いている方はお見送りとなります。(但し、企業都合退場は対象外)
※20代〜30代が中心で活気ある雰囲気です。
※成長意欲が高く、スキルを急速に伸ばしたい方に最適
※将来リーダーを目指す方歓迎
=====
※重要※
▼必ずお読みください▼
【必須要件】
・20~30代までの方、活躍中!
・社会人経験必須
・外国籍の場合、JLPT(N1)もしくはJPT700点以上のビジネス上級レベル必須
・週5日稼働必須
・エンジニア実務経験3年以上必須
=====
★本案件の最新の状況は、担当者までお問合せ下さい。
★期間:随時~
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。
【Node.js/TypeScript】自動車向けデータ分析プラットフォーム開発
業務委託(フリーランス)
Node.jsSparkTypeScriptKafka
バックエンドエンジニア
作業内容 【20代~40代の方向け】
自動車の走行データを解析・提供するプラットフォームのバックエンド開発です。
Node.js(TypeScript)を使用して、データストリームの処理、分析結果のAPI化、レポート作成機能の開発を担当します。
【AWS/フルリモート】ウェルネス・運動施設向けSaaSにおけるデータ基盤エンジニア(テックリード)の案件・求人
業務委託(フリーランス)
JavaPythonSQLSparkAWSGoogle Cloud PlatformSnowflakeCDKTerraformCloudFormation
作業内容 ・新データ基盤の設計・構築(AWS/BigQuery/Snowflake等)
・ETL/ELTパイプラインの改善・最適化
・データモデル設計/マルチテナント対応
・データガバナンス、セキュリティ設計・運用、コンプライアンス対応
・全社業務データ/IoTデータ/行動データの統合管理
・BIツール連携設計
・データ基盤運用・最適化、チーム技術育成・レビュー
(工程)要件定義、設計、構築、運用、最適化、技術リード
(開発環境)
言語:Python/Go/Java
クラウド:AWS/GCP/Snowflake
IaC:Terraform/CloudFormation/CDK
DWH:BigQuery/RDBMS
その他:Kafka/Pub/Sub/Spark/dbt/Trocco
※当案件におきましては、直近参画期間が半年以内の案件が続いている方はお見送りとなります。(但し、企業都合退場は対象外)
※20代〜30代が中心で活気ある雰囲気です。
※成長意欲が高く、スキルを急速に伸ばしたい方に最適
※将来リーダーを目指す方歓迎
=====
※重要※
▼必ずお読みください▼
【必須要件】
・20~30代までの方、活躍中!
・社会人経験必須
・外国籍の場合、JLPT(N1)もしくはJPT700点以上のビジネス上級レベル必須
・週5日稼働必須
・エンジニア実務経験3年以上必須
=====
★本案件の最新の状況は、担当者までお問合せ下さい。
★期間:随時~
バトル演出デザイナー/Unity・AfterEffects/ゲーム開発
業務委託(フリーランス)
Unity
3Dデザイナーデザイナー
作業内容 爽快マッチパズルゲームを代表作として、本格王道RPGゲームを中心にゲームの企画・開発を行う会社にて、ゲーム開発におけるバトル演出デザイナー業務をお任せします。
■□具体的には…□■
・キャラクター、モンスターの必殺技/魔法演出作成(Unity/Photoshop/AfterEffects/SPARK GEARを使用)
<こんな方におすすめです!>
・スキルアップしたい方
・ゲーム開発に携わりたい方
【Java/リモート併用】広告配信システム・社内向けのWeb管理画面のバックエンド開発の案件・求人
業務委託(フリーランス)
JavaScala
バックエンドエンジニア
作業内容 国内最大級のインターネット広告配信プラットフォームのシステムの設計、開発。
広告配信システム、大規模データ処理、分析、Web開発など多様な領域で開発を行う事ができ、多様なスキルを求められることになります。
・広告配信システムのサーバサイド開発
・広告配信システムや社内向けのWeb管理画面開発
・Hadoopなどの大規模データ向け基盤を活用した開発
【開発環境】
言語:Scala, Kotlin, Python, Java
DB:MySQL
KVS:Redis
データ基盤:Hadoop(Hive, Spark)
その他ミドルウェア:Apache Kafka, Docker
インフラストラクチャ:オンプレミス、GCP、AWS
バージョン管理システム:Git(Github Enterprise)
コラボレーションツール:Slack, Workplace, Confluence, JIRA, Google Workspace
■作業環境__:Windows/Mac選択可
※当案件におきましては、直近参画期間が半年以内の案件が続いている方はお見送りとなります。(但し、企業都合退場は対象外)
※20代〜30代が中心で活気ある雰囲気です。
※成長意欲が高く、スキルを急速に伸ばしたい方に最適
※将来リーダーを目指す方歓迎
=====
※重要※
▼必ずお読みください▼
【必須要件】
・20~30代までの方、活躍中!
・社会人経験必須
・外国籍の場合、JLPT(N1)もしくはJPT700点以上のビジネス上級レベル必須
・週5日稼働必須
・エンジニア実務経験3年以上必須
=====
★本案件の最新の状況は、担当者までお問合せ下さい。
★期間:随時~
【Python】ビッグデータ処理分析開発
業務委託(フリーランス)
PythonSpark
データサイエンティスト
作業内容 世界的に普及が進んでいる大規模分散処理フレームワークのApacheSpark/Python/Scala
【クラウドエンジニア(AWS)】【業務委託(準委任)】環境設計レビュー・改善・実装・メンテナンス
MySQLDynamoDBSparkAWSApacheRedshiftGlue
作業内容 ■概要
環境設計レビュー・改善・実装・メンテナンスをお任せいたします。
■具体的な作業内容
以下の業務をお願いします。
・既存のAWS ETL環境の調査改善
・メンテ作業の手順化および運用作業(テーブル追加やカラム変更程度)
※対象環境はミッションクリティカルではないデータ処理基盤となります。
【クラウドエンジニア(AWS) / リモート案件紹介可能】AWS・GCPを活用したデータ基盤整備と移行プロジェクト
業務委託(フリーランス)
AWSGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
AWSデータレイクからBigQueryへのデータ移行作業や、GCPデータ基盤の整備を行うプロジェクトです。PythonやSparkを活用し、データ基盤の設計・開発を進めるとともに、効率的なデータ処理環境を構築します。TerraformやCI/CDツールを利用した開発プロセスにも携わります。
■具体的な業務内容
・AWSデータレイク(S3 + Glue data catalog)からBigQueryへのデータ移行
・GCPデータ基盤の整備およびワークフローエンジンの導入
・PythonやSparkを使用したアプリケーション開発および保守
・TerraformやCI/CDツールを利用した開発環境の整備
・データ基盤設計および運用改善
【クラウドエンジニア(AWS)】【業務委託(準委任)】クラウドを使用した製品利用ログ分析基盤の開発・運用
作業内容 ■概要
Redshift (PostgreSQL)上のDBテーブル設計、クエリ開発をお任せいたします。
■具体的な作業内容
・AWS EMRを使用したETL、データ前処理(Python、Spark)
【クラウドエンジニア(AWS) / リモート案件紹介可能】AWSおよびGCPを活用したデータ基盤整備プロジェクト
業務委託(フリーランス)
AWSGoogle Cloud Platform
作業内容 ※エンジニアとしての実務経験が2年以上ある方が対象の案件です!!
■概要
AWSおよびGCP環境でのデータ基盤整備プロジェクトです。データレイクからBigQueryへの移行作業や、GCPのデータ基盤整備を担当します。PythonやSparkを活用し、TerraformやCI/CDツールを使用した効率的な基盤開発を進めます。
■具体的な業務内容
・AWSのデータレイク(S3+Glue data catalog)からBigQueryへのデータ移行作業
・GCPデータ基盤の設計および整備(ワークフローエンジン導入など)
・AWS上で動作するアプリケーションの課題発見および解決
・Python、Hive、Sparkを使用したデータ基盤の構築
【Python(Web開発系)】データ基盤サービスの設計開発運用
業務委託(フリーランス)
PythonSQLSpark
作業内容 【業務内容】
データドリブンでの意思決定を支えるデータ基盤の設計・開発・運用に携わり、データアナリストやマーケティング、アプリケーションエンジニアと協力しながら事業課題の解決を行います。
【作業内容】
・データ基盤の設計
・Pythonを用いたデータ処理・ETL開発
・データ分析用の環境構築
・テストおよび運用フローの整備
・関係者との調整および改善提案
設定していない条件はありませんか?
スキル・リモート・単価などで絞り込み、
効率よく案件を探せます。